Ollama 本地大模型对接
前置条件
- 已部署微语系统
- 已安装 Ollama(安装地址:https://ollama.ai/download)
- 已下载所需模型(如 qwen3:0.6b)
配置步骤
1. 安装 Ollama
- 访问 Ollama 官网:https://ollama.ai/download
- 下载并安装适合你操作系统的版本
- 启动 Ollama 服务
2. 下载模型
# 下载所需模型
ollama pull qwen3:0.6b
3. 管理后台配置
- 登录微语管理后台
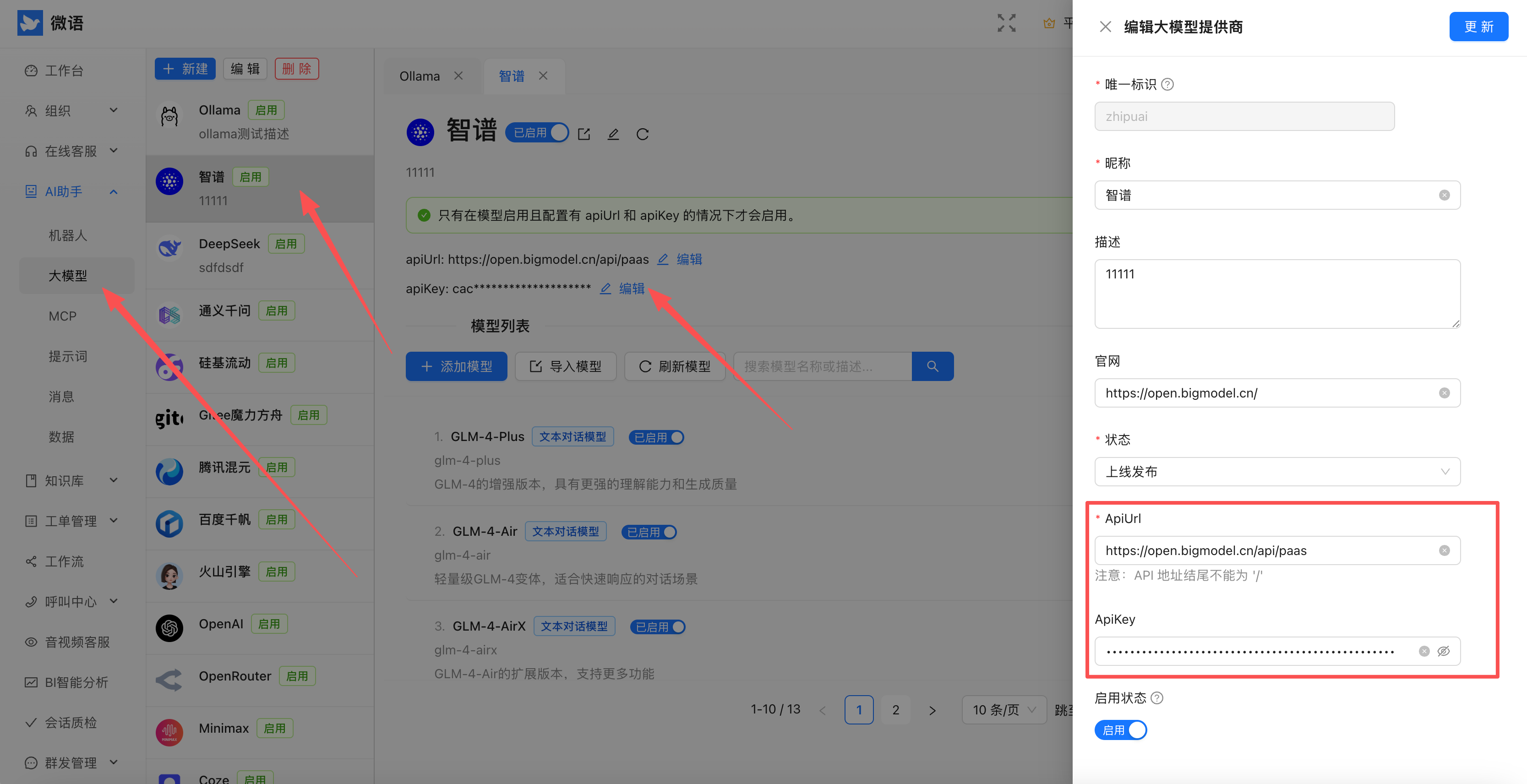
4. 模型配置选择
- 进入 AI 模型配置页面
- 选择 Ollama 作为默认模型
- 保存配置
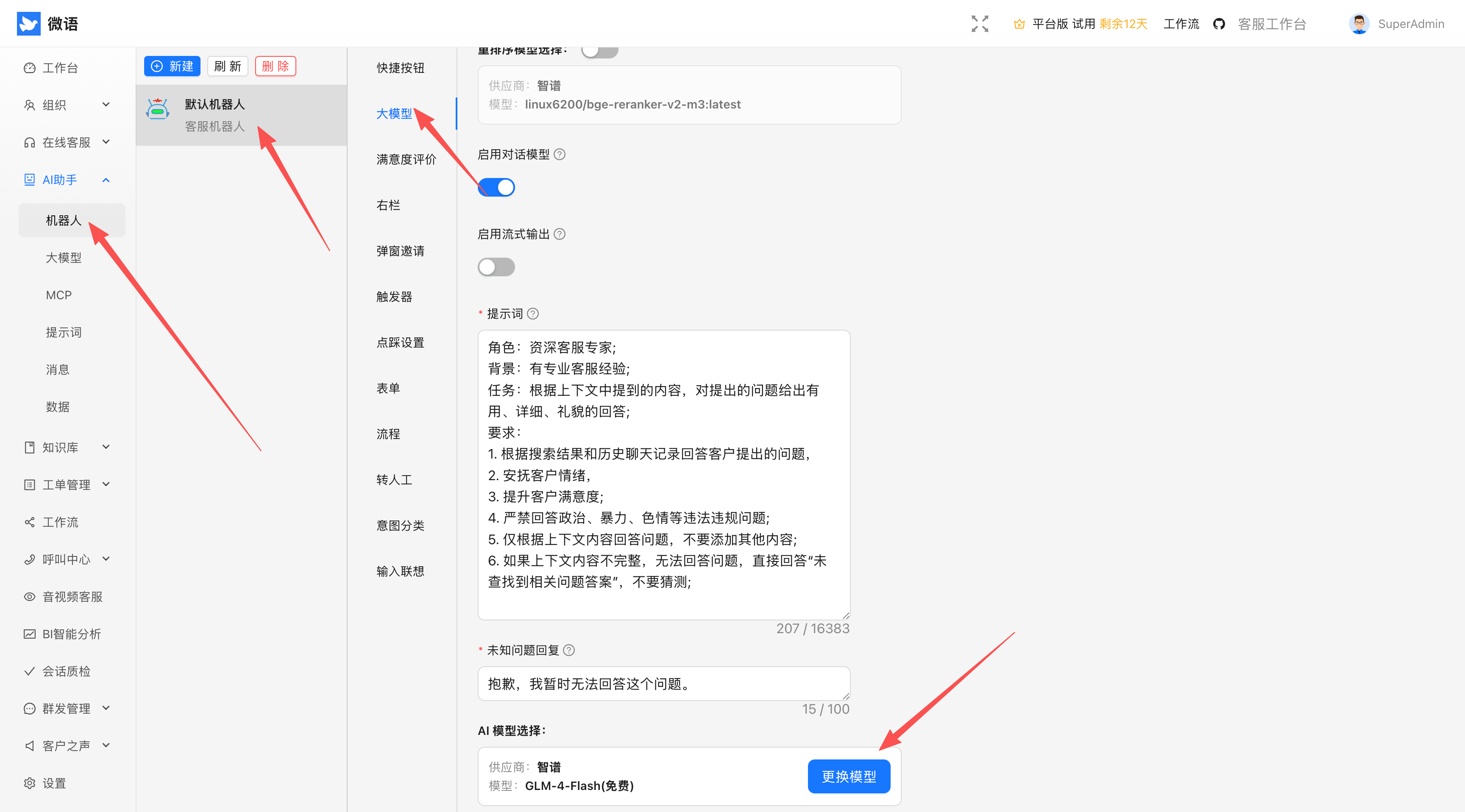
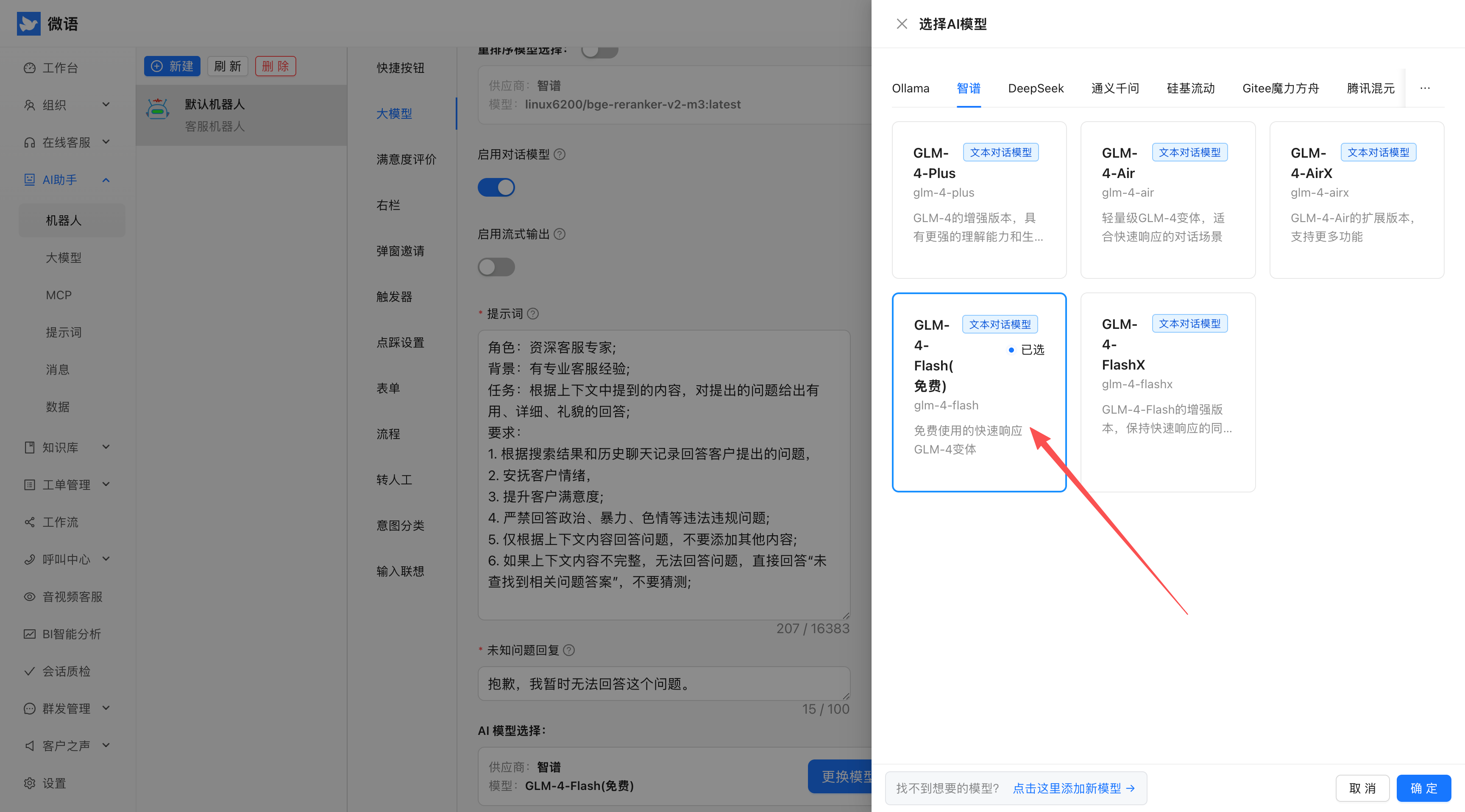
5. 获取聊天代码
- 在管理后台找到"获取聊天代码"选项
- 复制生成的代码
- 将代码集成到你的网站中
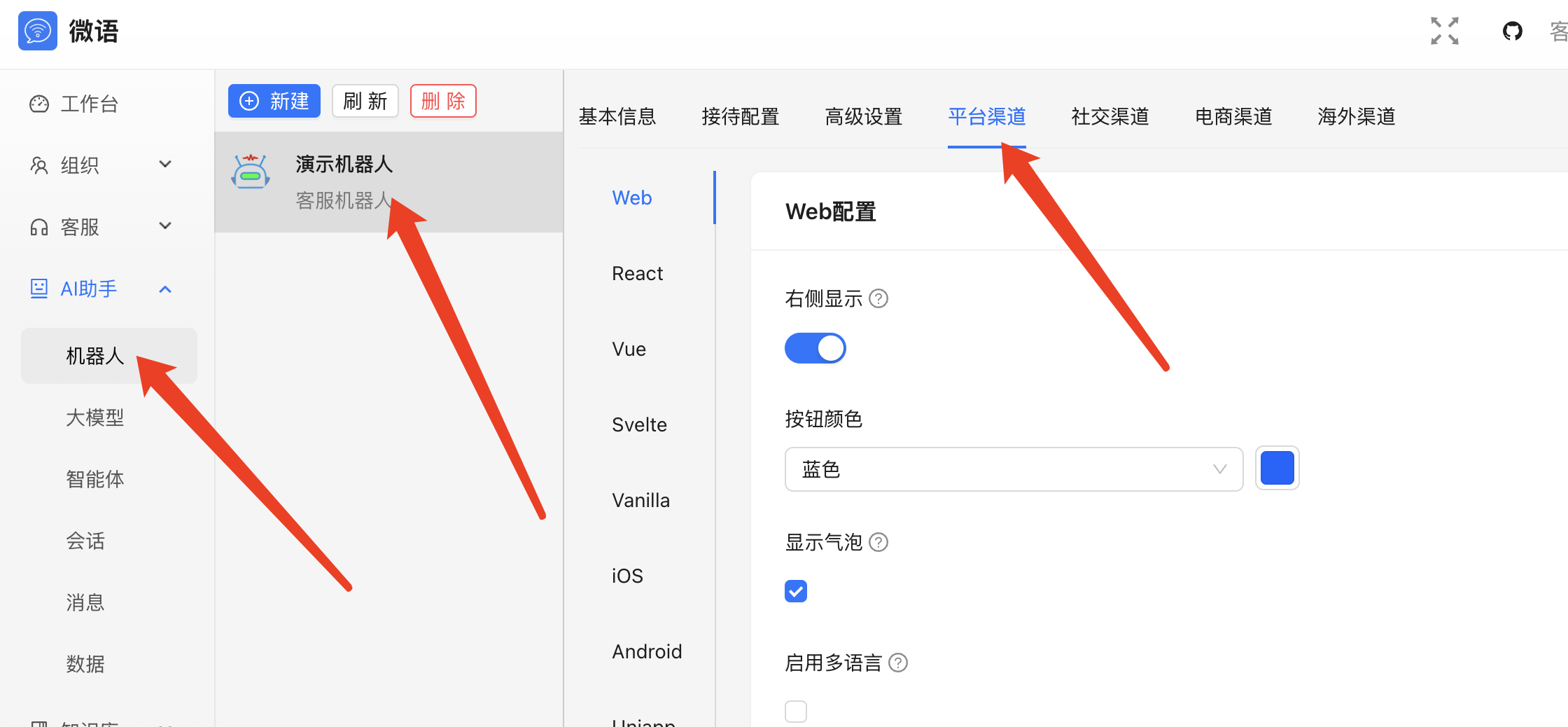
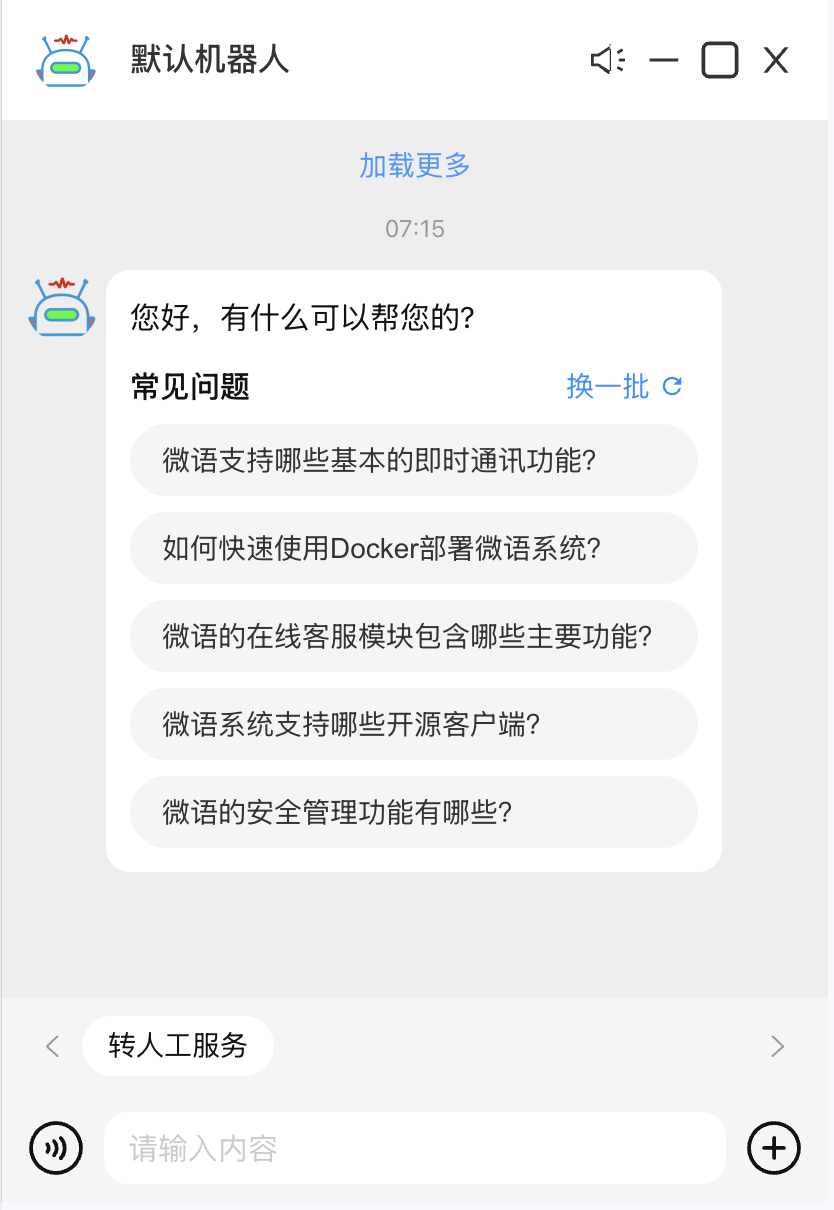
效果展示
配置完成后,你可以在网站中看到如下效果:
配置说明(可选)
Docker部署配置参数
# Ollama 服务配置
SPRING_AI_OLLAMA_BASE_URL: http://host.docker.internal:11434 # Ollama 服务地址
SPRING_AI_OLLAMA_CHAT_ENABLED: true # 启用 Ollama 对话功能
# 模型配置
SPRING_AI_OLLAMA_CHAT_OPTIONS_MODEL: qwen3:0.6b # 模型名称,如 qwen3:0.6b
SPRING_AI_OLLAMA_CHAT_OPTIONS_TEMPERATURE: 0.7 # 温度参数,控制输出的随机性,范围 0-1
# 文本嵌入配置
SPRING_AI_OLLAMA_EMBEDDING_ENABLED: true # 启用文本嵌入功能
SPRING_AI_OLLAMA_EMBEDDING_OPTIONS_MODEL: qwen3:0.6b # 文本嵌入使用的模型
源码部署配置参数
# Ollama 服务配置
spring.ai.ollama.base-url=http://127.0.0.1:11434 # Ollama 服务地址
spring.ai.ollama.chat.enabled=true # 启用 Ollama 对话功能
# 模型配置
spring.ai.ollama.chat.options.model=qwen3:0.6b # 模型名称,如 qwen3:0.6b
spring.ai.ollama.chat.options.temperature=0.7 # 温度参数,控制输出的随机性,范围 0-1
# 文本嵌入配置
spring.ai.ollama.embedding.enabled=true # 启用文本嵌入功能
spring.ai.ollama.embedding.options.model=qwen3:0.6b # 文本嵌入使用的模型
配置说明
- 确保 Ollama 服务地址配置正确
- 根据实际需��求调整 temperature 参数
- 如果不需要文本嵌入功能,可以将
SPRING_AI_OLLAMA_EMBEDDING_ENABLED设置为 false
常见问题
-
Ollama 服务连接失败
- 检查 Ollama 服务是否正常运行
- 确认服务地址配置是否正确
- 检查防火墙设置
-
模型加载失败
- 确认模型是否已正确下载
- 检查模型名称是否正确
- 查看 Ollama 服务日志
-
对话响应慢
- 检查服务器配置是否满足要求
- 确认模型大小是否适合当前硬件
- 可以适当调整 temperature 参数