ASR 能力介绍
微语客服系统支持 ASR(Automatic Speech Recognition,自动语音识别)能力,可将语音内容实时或离线转换为文本,适用于语音消息转文字、语音输入辅助、客服质检、音视频内容文本化等场景。
一、ASR 可以解决什么问题
客服工作中,客户可能通过语音消息、语音输入、通话录音或音频文件描述问题。如果仅依赖人工听取,不仅效率低,还会影响检索、归档和自动化分析。
接入 ASR 后,微语可以帮助企业实现:
- 将客户语音消息快速转成文字
- 支持客服通过语音输入生成文本内容
- 为语音内容建立可搜索、可归档、可分析的数据基础
- 为 AI 总结、质检、工单处理和自动回复提供文本输入
二、微语已支持的 ASR 能力
当前版本已支持以下 ASR 相关能力:
1. 管理后台 ASR 测试与配置
管理后台已提供 ASR 测试入口,支持上传语音文件进行识别,也支持直接调用麦克风进行识别测试。
测试调用会同步记录到 AsrEntity 表中,便于统一查看识别记录、定位问题和评估识别效果。
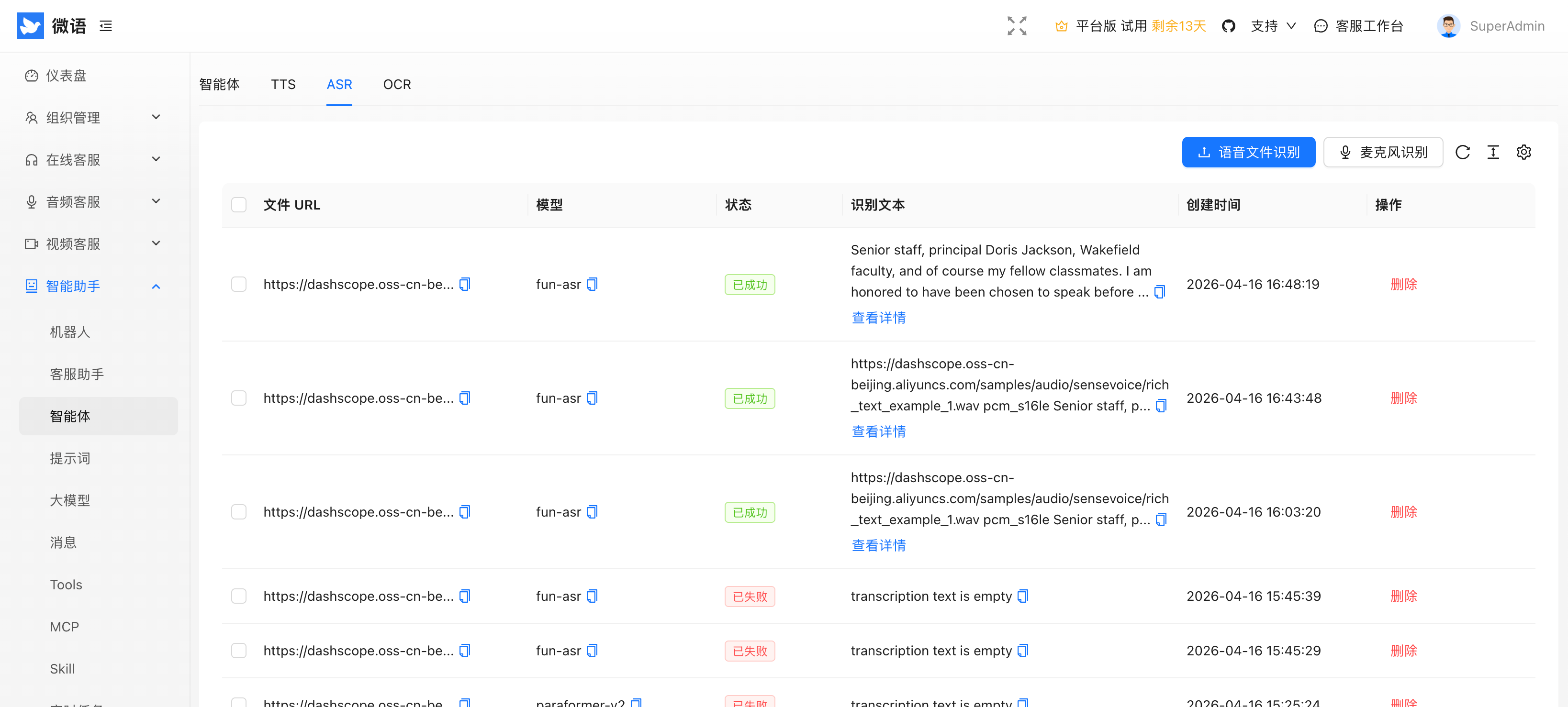
语音文件识别
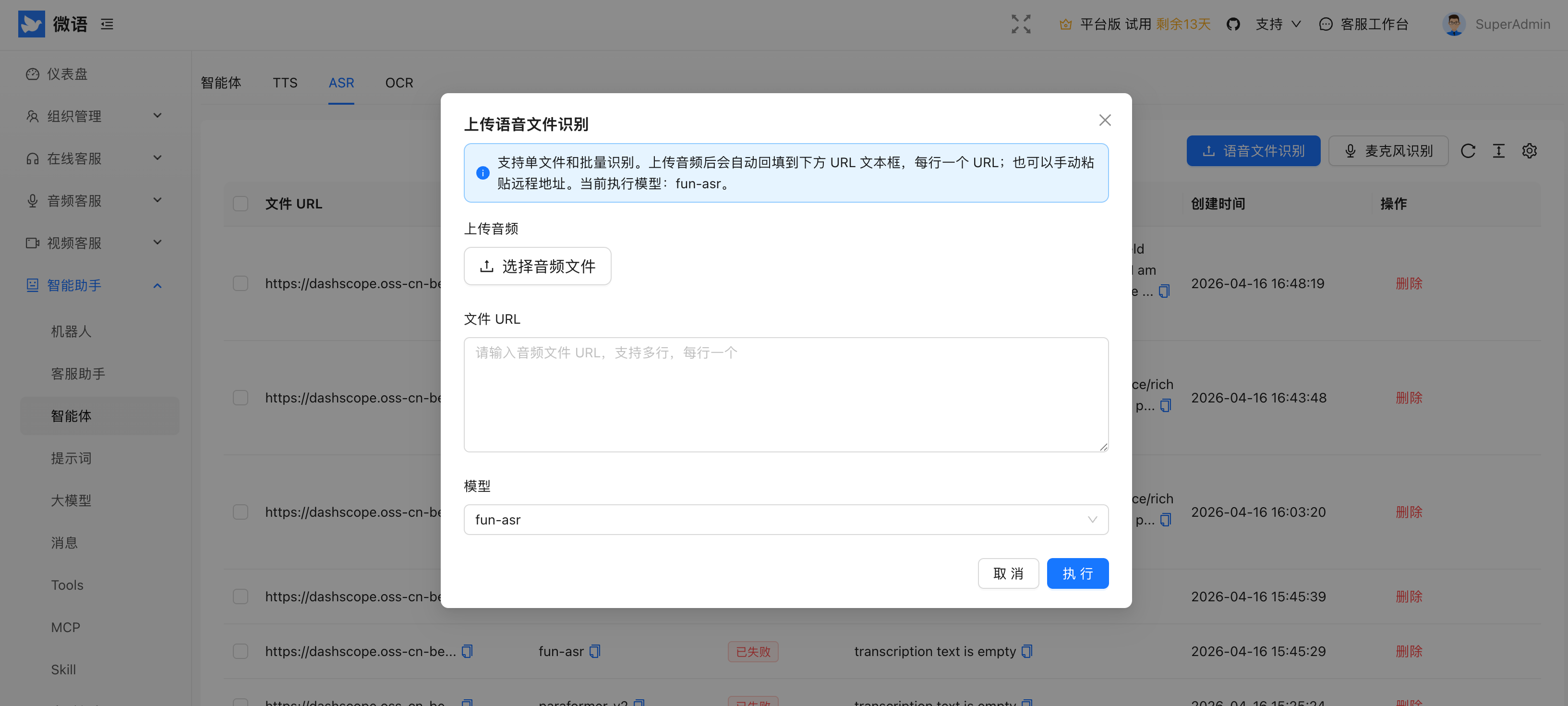
麦克风识别
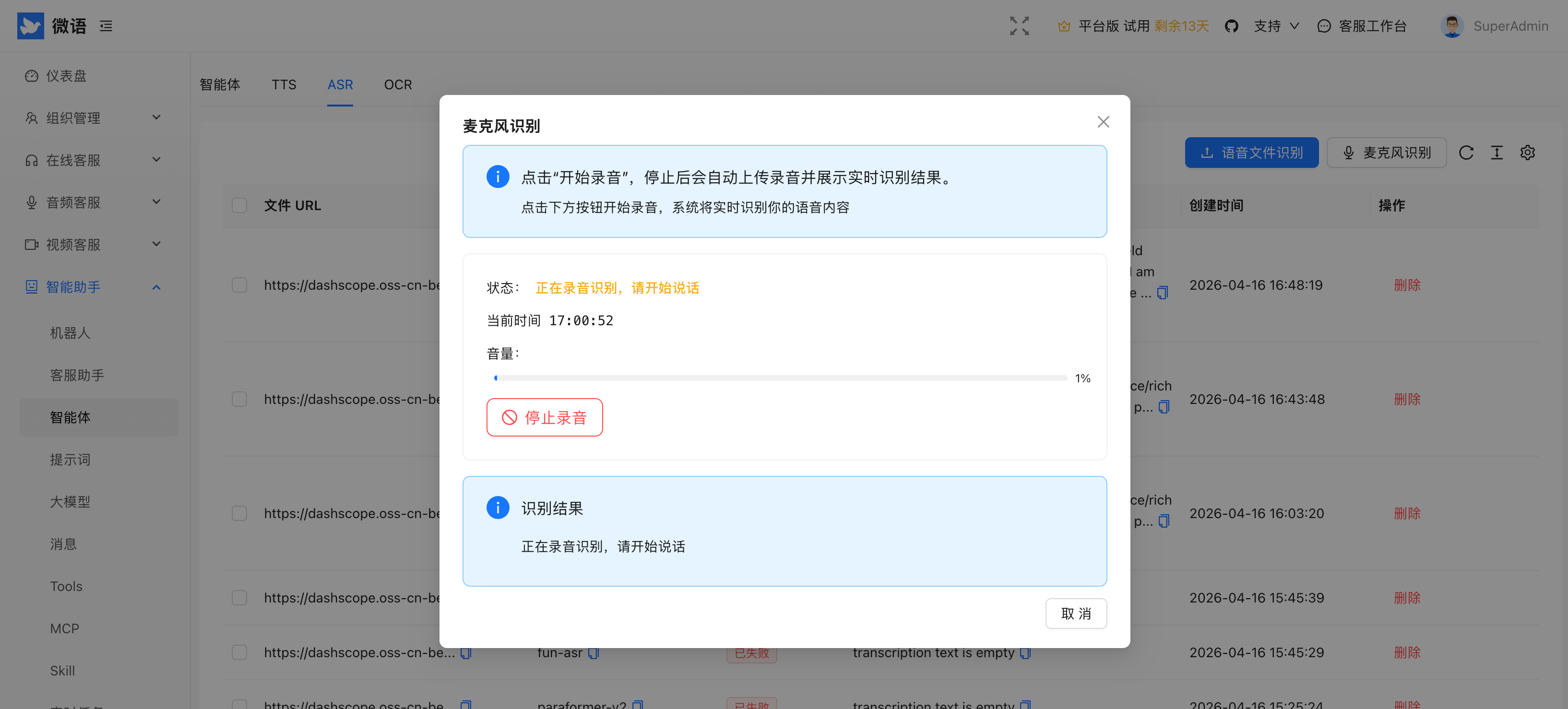
2. 客服工作台语音输入转文字
在 desktop 客服端中,SpeechInputModal 已支持语音输入转文字。客服可以通过语音说话生成文本内容,再直接用于发送或编辑。
该识别过程的调用记录也会同步写入 AsrEntity,便于后续审计和统计。
语音输入
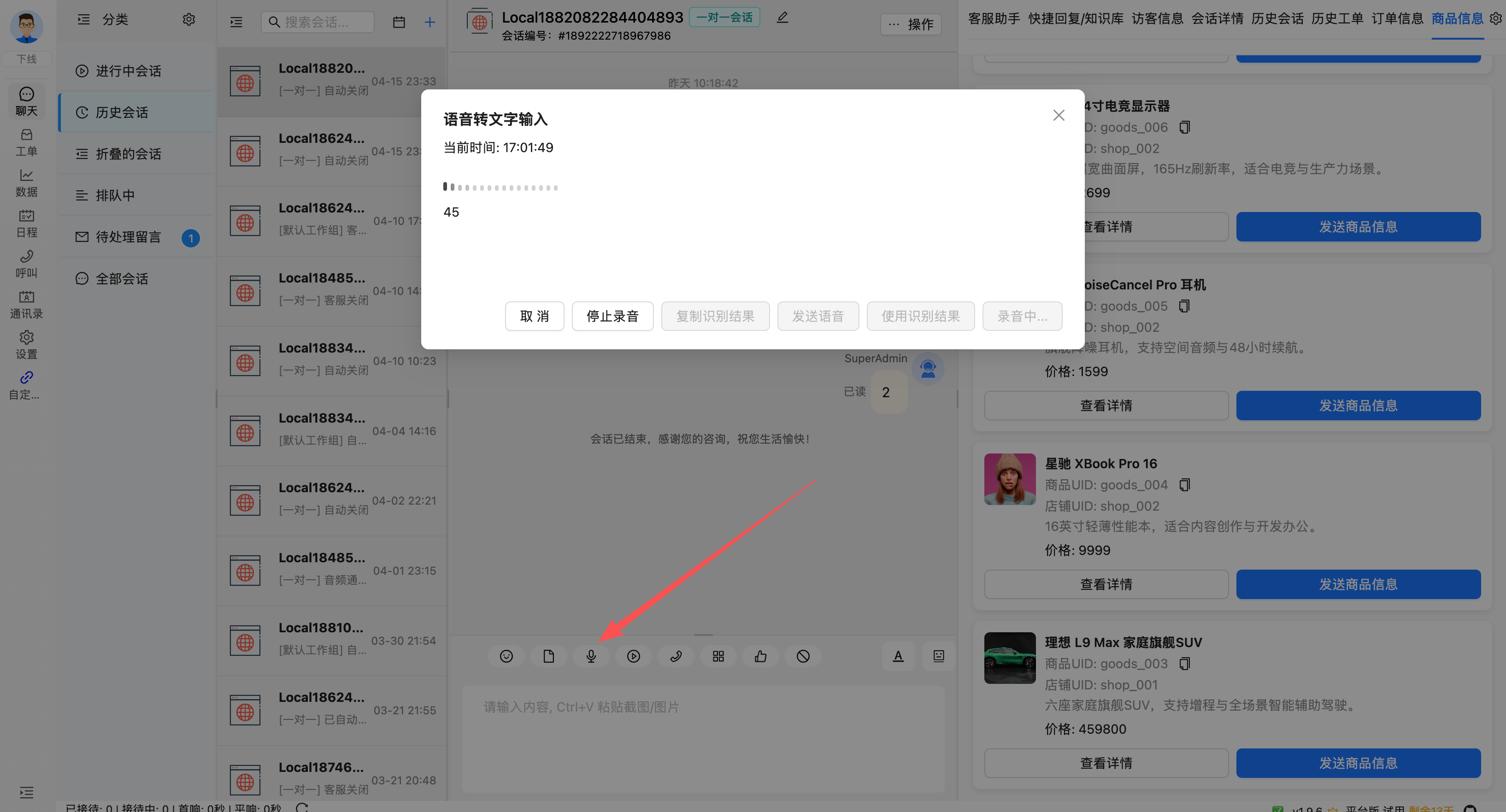
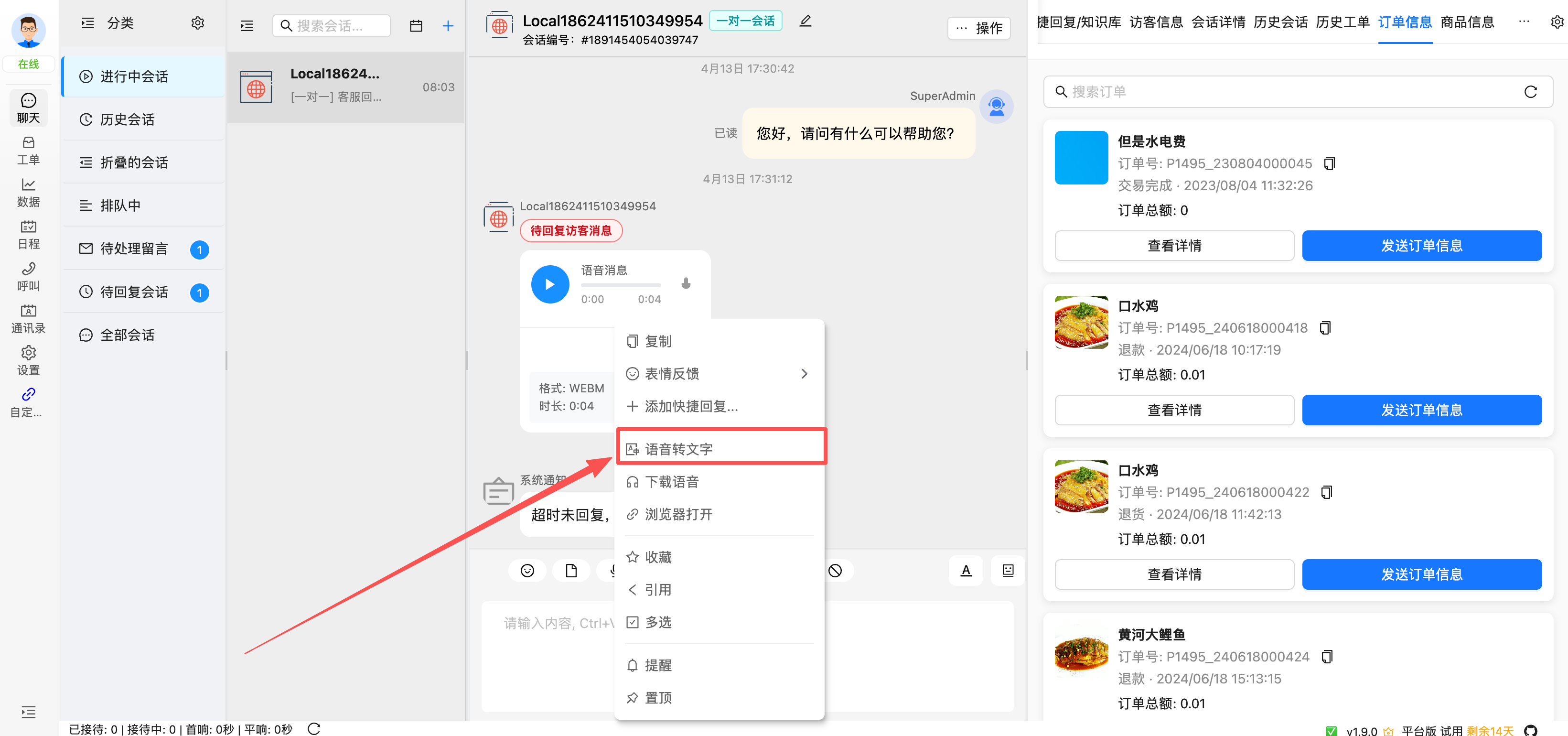
3. 语音消息一键转文字
在 desktop 客服端中,客服可对语音消息使用右键菜单,直接执行语音转文字。
转换完成后,可将语音内容以文本形式展示和复用,适用于:
- 客户发送语音问题描述
- 客服需要快速浏览语音内容而非反复试听
- 后续需要把语音信息转入工单、知识库或统计系统
这一路径的识别记录同样会保存到 AsrEntity 表中。
三、项目 ASR 配置说明
微语当前的 ASR 能力主要基于 DashScope 提供,但实际执行并不是简单依赖通用的 Spring AI 自动路由,而是由项目内部的 ASR 执行链路统一承接。因此在对接时,除了看 provider 开关,也要关注默认模型、实时模型、源格式和轮询超时等项目级参数。
1. 启用音频与 ASR 能力
项目首先通过统一的音频模型配置声明当前音频 provider,并单独打开 DashScope 语音识别能力:
spring.ai.model.audio=dashscope
spring.ai.model.audio.speech=none
spring.ai.model.audio.transcription=none
spring.ai.dashscope.enabled=true
spring.ai.dashscope.audio.transcription.enabled=true
这些配置的含义是:
spring.ai.model.audio=dashscope:将项目音频能力默认路由到 DashScopespring.ai.dashscope.enabled=true:启用 DashScope 提供方spring.ai.dashscope.audio.transcription.enabled=true:启用语音识别能力
这里需要特别注意,spring.ai.model.audio.transcription 当前仍保留为 none。这和 TTS 场景类似,说明当前 ASR 主要由项目内部的 DashScope ASR 实现承接,而不是完全依赖通用 Spring AI 的 transcription 自动装配链路。
2. DashScope API Key 与端点
当前项目使用阿里云百炼官方端点:
spring.ai.dashscope.base-url=https://dashscope.aliyuncs.com
spring.ai.dashscope.api-key=ENC(...)
# spring.ai.dashscope.audio.transcription.api-key=
这里需要注意:
spring.ai.dashscope.base-url指向百炼正式接口地址spring.ai.dashscope.api-key是全局 DashScope Key,可同时服务于文本、TTS、ASR 等能力spring.ai.dashscope.audio.transcription.api-key是可选的 ASR 专用 Key;如果未单独配置,系统会自动回退到spring.ai.dashscope.api-key
如果企业希望把语音识别与文本模型调用分开做权限隔离,可以单独配置 transcription 专用 Key;如果只是常规接入,直接复用全局 DashScope Key 即可。
3. ASR 默认模型与实时模型
当前项目里已经显式定义了默认离线模型和实时模型:
spring.ai.dashscope.audio.transcription.options.model=paraformer-v2
spring.ai.dashscope.audio.transcription.realtime-model=paraformer-realtime-v2
它们的作用分别是:
spring.ai.dashscope.audio.transcription.options.model:定义离线文件识别的默认模型,当前默认值为paraformer-v2spring.ai.dashscope.audio.transcription.realtime-model:定义实时语音识别默认模型,当前默认值为paraformer-realtime-v2
这两个配置会影响后端执行接口的默认模型选择,也会影响管理后台测试页的默认模型展示,因此它们属于项目级默认参数,而不是单纯的底层 SDK 备用值。
4. 当前实现里的执行路径差异
结合当前实现,ASR 并不是所有文件都走同一条链路,而是根据文件地址类型自动分流:
- 公网可访问音频 URL:优先走 DashScope 录音文件转写任务
- 本地文件或私有 URL:优先走本地文件识别链路
这两条路径在模型选择上也有差异:
- 公网 URL 场景下,系统默认更偏向离线文件识别模型,当前默认值来源于
spring.ai.dashscope.audio.transcription.options.model - 本地文件或私有 URL 场景下,后端会优先切换到更适合本地识别链路的模型,当前代码中的兜底模型为
fun-asr-realtime
另外,当前后端会根据音频格式自动决定是否先通过 ffmpeg 转成 16k 单声道 wav 再送入识别链路,因此如果部署环境需要识别�本地上传文件,建议同时确保容器或宿主机中具备 ffmpeg。
5. 项目级 ASR 默认源格式、超时与轮询间隔
除了 DashScope 提供方配置,项目还维护了一组更贴近业务执行接口和管理后台测试页的默认参数:
bytedesk.ai.asr.source-format=mp3
bytedesk.ai.asr.timeout-ms=180000
bytedesk.ai.asr.poll-interval-ms=1500
它们的意义是:
bytedesk.ai.asr.source-format:默认源音频格式,管理台和执行接口会共享这一默认值bytedesk.ai.asr.timeout-ms:异步转写任务的最长等待时间bytedesk.ai.asr.poll-interval-ms:异步转写结果查询轮询间隔
当前默认组合为 mp3 + 180000ms + 1500ms,适合常见客服语音文件和普通公网 URL 转写场景。如果企业上传的是时长较长的录音,或者网络环境对 OSS 结果下载存在波动,可以适当提高 timeout-ms。
6. Docker Compose 部署下的配置说明
如果项目通过 Docker Compose 部署,那么同一套 ASR 配置会以环境变量形式出现在容器编排文件中,例如 deploy/docker/compose-app-bytedesk.yaml。
在 Compose 场景下,properties 写法与环境变量写法的关系大致如下:
spring.ai.model.audio=dashscope
spring.ai.dashscope.enabled=true
spring.ai.dashscope.audio.transcription.enabled=true
spring.ai.dashscope.audio.transcription.api-key=
spring.ai.dashscope.audio.transcription.options.model=paraformer-v2
spring.ai.dashscope.audio.transcription.realtime-model=paraformer-realtime-v2
bytedesk.ai.asr.source-format=mp3
bytedesk.ai.asr.timeout-ms=180000
bytedesk.ai.asr.poll-interval-ms=1500
对应到 Compose 环境变量通常是:
SPRING_AI_MODEL_AUDIO: dashscope
SPRING_AI_DASHSCOPE_ENABLED: "true"
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_ENABLED: "true"
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_API_KEY: ${SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_API_KEY:-}
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_OPTIONS_MODEL: paraformer-v2
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_REALTIME_MODEL: paraformer-realtime-v2
BYTEDESK_AI_ASR_SOURCE_FORMAT: mp3
BYTEDESK_AI_ASR_TIMEOUT_MS: 180000
BYTEDESK_AI_ASR_POLL_INTERVAL_MS: 1500
这里可以重点关注 4 类变量:
SPRING_AI_MODEL_AUDIO:声明音频能力默认 providerSPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_ENABLED:显式开启 DashScope ASRSPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_OPTIONS_MODEL与SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_REALTIME_MODEL:定义容器部署下的默认离线模型与实时模型BYTEDESK_AI_ASR_SOURCE_FORMAT、BYTEDESK_AI_ASR_TIMEOUT_MS、BYTEDESK_AI_ASR_POLL_INTERVAL_MS:定义管理台表单和执行接口共享的默认业务参数
需要注意的是,当前仓库里的 Compose 示例默认将:
SPRING_AI_MODEL_AUDIO配成了zhipuaiSPRING_AI_DASHSCOPE_ENABLED配成了falseSPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_ENABLED配成了falseSPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_OPTIONS_MODEL配成了qwen3-asr-flashSPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_REALTIME_MODEL配成了fun-asr-realtime
这意味着如果直接使用当前默认 Compose 配置启动,DashScope ASR 实际上是关闭状态;同时 Compose 示例里的模型默认值也更偏向容器部署下的实际可用配置,而不完全等同于本地 properties 示例中的 paraformer-v2 / paraformer-realtime-v2。
如果你希望在 Docker Compose 部署中启用当前文档所描述的 DashScope ASR,至少需要把这些变量调整为:
SPRING_AI_MODEL_AUDIO: dashscope
SPRING_AI_DASHSCOPE_ENABLED: "true"
SPRING_AI_DASHSCOPE_API_KEY: ${SPRING_AI_DASHSCOPE_API_KEY:-}
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_ENABLED: "true"
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_API_KEY: ${SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_API_KEY:-}
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_OPTIONS_MODEL: paraformer-v2
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_REALTIME_MODEL: paraformer-realtime-v2
BYTEDESK_AI_ASR_SOURCE_FORMAT: mp3
BYTEDESK_AI_ASR_TIMEOUT_MS: 180000
BYTEDESK_AI_ASR_POLL_INTERVAL_MS: 1500
其中:
- 如果
SPRING_AI_DASHSCOPE_AUDIO_TRANSCRIPTION_API_KEY留空,系统会回退到SPRING_AI_DASHSCOPE_API_KEY - 如果只是快速验证后台上传识别或公网 URL 转写,保留
mp3 + 180000 + 1500即可 - 如果部署场景依赖本地上传文件识别,建议同时确认镜像内具备
ffmpeg - 如果要做生产部署,建议配合
.env文件或 CI/CD Secret 管理 API Key,而不要直接把明文 Key 写进 Compose 文件
7. 推荐配置方式
对于大多数企业接入,建议按下面顺序完成配置:
- 确认
spring.ai.model.audio=dashscope - 确认
spring.ai.dashscope.enabled=true - 配置
spring.ai.dashscope.api-key,必要时单独补充spring.ai.dashscope.audio.transcription.api-key - 根据主要业务场景选择默认离线模型和实时模型
- 根据上传音频格式和识别任务时长调整
bytedesk.ai.asr.source-format、bytedesk.ai.asr.timeout-ms和bytedesk.ai.asr.poll-interval-ms - 如果包含本地文件识别场景,确认运行环境具备
ffmpeg
如果只是本地开发或管理后台试听验证,保持当前默认配置即可;如果是面向生产环境,建议同时明确模型策略、超时策略、私有文件解析策略以及本地音频转码依赖。
四、典型应用场景
1. 语音客服辅助输入
- 客服通过语音输入快速组织回复内容
- 降低长文本录入成本
- 提升接待效率
2. 客户语音消息处理
- 将客户语音消息快速转成文本
- 方便复制、检索、转发和归档
- 便于主管复盘和质检
3. AI 与自动化处理
- 将语音内容转成文本后交由机器人理解
- 用于自动摘要、会话分析、意图识别
- 作为工单流转、知识匹配、情绪分析的基础输入
五、能力价值
微语 ASR 能力的核心价值在于:
- 让语音内容具备和文本同等的可处理性
- 降低客服听音成本
- 提升语��音沟通场景下的处理速度
- 为质检、统计、AI 分析提供结构化文本基础
六、推荐使用方式
建议企业按照以下方式落地 ASR:
- 管理员先在后台完成模型测试和识别效果验证
- 客服在工作台中使用语音输入和语音消息转文字能力
- 将识别结果结合会话小结、工单、知识库和机器人继续处理
七、总结
微语已具备完整的客服向 ASR 基础能力,包括后台测试、前端语音输入转文字、语音消息一键转文字以及识别记录落库。对于语音沟通频繁的客服团队,这项能力能够明显提升处理效率,并为后续 AI 自动化和质检分析提供可靠的数据基础。